
티스토리 뷰
-- ------------------------------------------------------
-- + 연습
-- ------------------------------------------------------
SELECT
last_name,
salary
FROM
employees
WHERE
salary > (
SELECT
salary
FROM
employees
WHERE
last_name = 'Whalen'
)
ORDER BY
salary ASC;
-- 'Whalen'보다 많은 월급을 받고 있는 직원의 이름, 월급을 월급을 기준으로 오름차순 정렬하여 출력한다.
SELECT
last_name,
salary,
( SELECT department_name
FROM departments
WHERE employees.department_id = departments.department_id ) AS "소속부서"
FROM
employees
WHERE
salary > (
SELECT
salary
FROM
employees
WHERE
last_name = 'Whalen'
);
-- 'Whalen'보다 많은 월급을 받고 있는 직원의 이름, 월급 그리고 소속부서를 출력한다.
-- SELECT절에 작성되어 있는 서브쿼리의 경우에는 단독으로 실행이 불가능하기에 상관 서브쿼리에 속한다.
-- 조인으로 했던 것을 이와 같이 서브쿼리로도 해결할 수 있다.
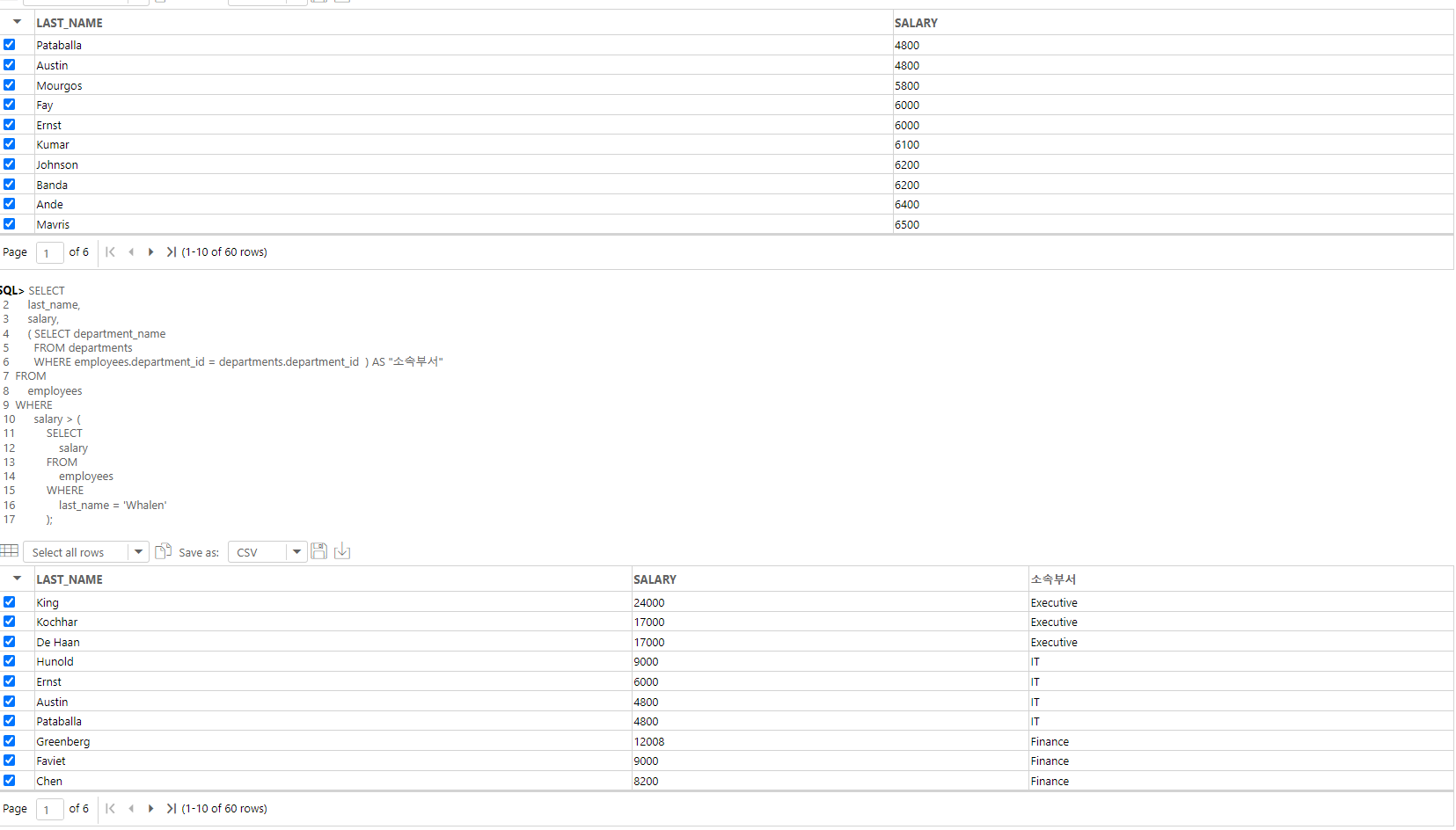
-- 셀프조인으로 각 사원의 이름과 관리자의 이름을 출력해 보자! (***)
SELECT
e.employee_id AS 사원번호,
e.last_name AS 사원명,
m.employee_id AS 관리자번호,
m.last_name AS 관리자명
FROM
employees e,
employees m
WHERE
e.manager_id = m.employee_id
ORDER BY
e.employee_id ASC;
-- 셀프조인을 활용하여 직원의 사원번호와 관리자의 사원번호, 그리고 각각의 이름을 출력하였다.

-- 서브쿼리 사용버전 (****)
SELECT
employee_id,
t1.last_name,
manager_id,
( SELECT last_name FROM employees t2 WHERE t2.employee_id = t1.manager_id ) AS 관리자명
FROM
employees t1;
-- 서브쿼리를 통해서 셀프조인을 하지 않고서 셀프조인과 같은 역할을 수행하도록 하였다.
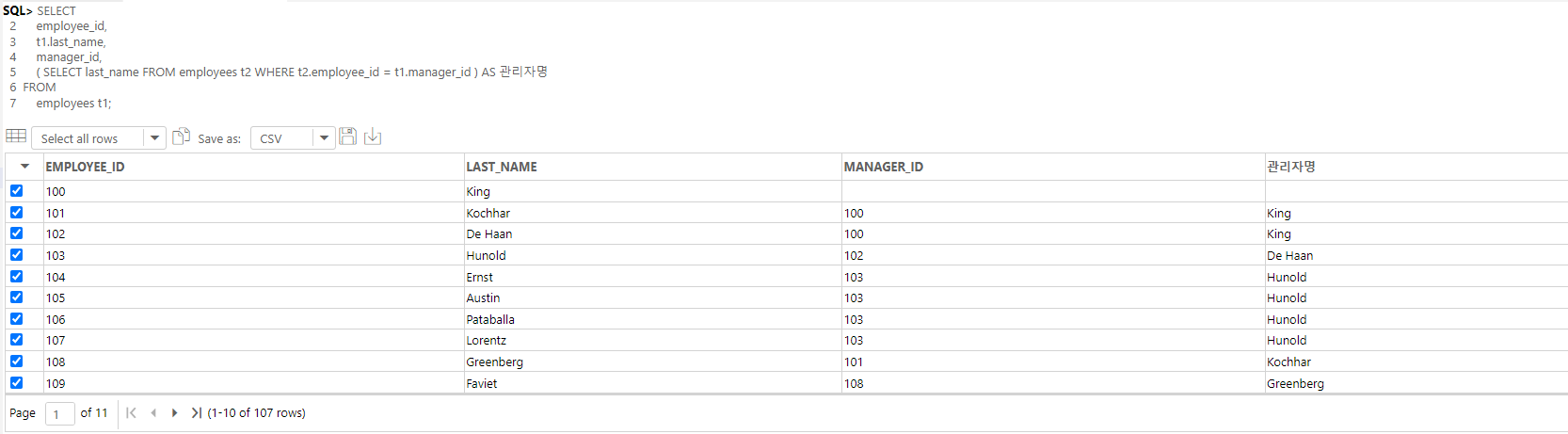
-- IT부서 프로그래머의 이름과 급여와 평균급여를 출력하여라 (**)
SELECT
last_name,
salary,
( SELECT avg(salary) FROM employees WHERE job_id = 'IT_PROG' ) AS "평균급여"
FROM
employees
WHERE
job_id = 'IT_PROG';
-- IT부서의 프로그래머 월급 평균을 각각의 프로그래머 이름, 월급과 함께 출력한다.
-- 우리 회사의 전체 부서를 대상으로 각 부서번호와 그 소속 사원수를 출력해라. (**)
SELECT
department_id AS "부서 번호",
count(employee_id) "사원 수",
( -- 부서번호가 t1이랑 t2가 같은 것만 부서 이름을 출력한다.
SELECT department_name
FROM departments t2
WHERE t2.department_id = t1.department_id
) AS "부서명"
FROM
employees t1
GROUP BY
department_id
ORDER BY
department_id ASC;
-- NULL값은 가장 큰 수로 취급이 되기에, 부서가 없는 1명의 직원은 마지막에 출력된다.
-- 조인할 때에는 별칭을 사용하는 것이 좋다.
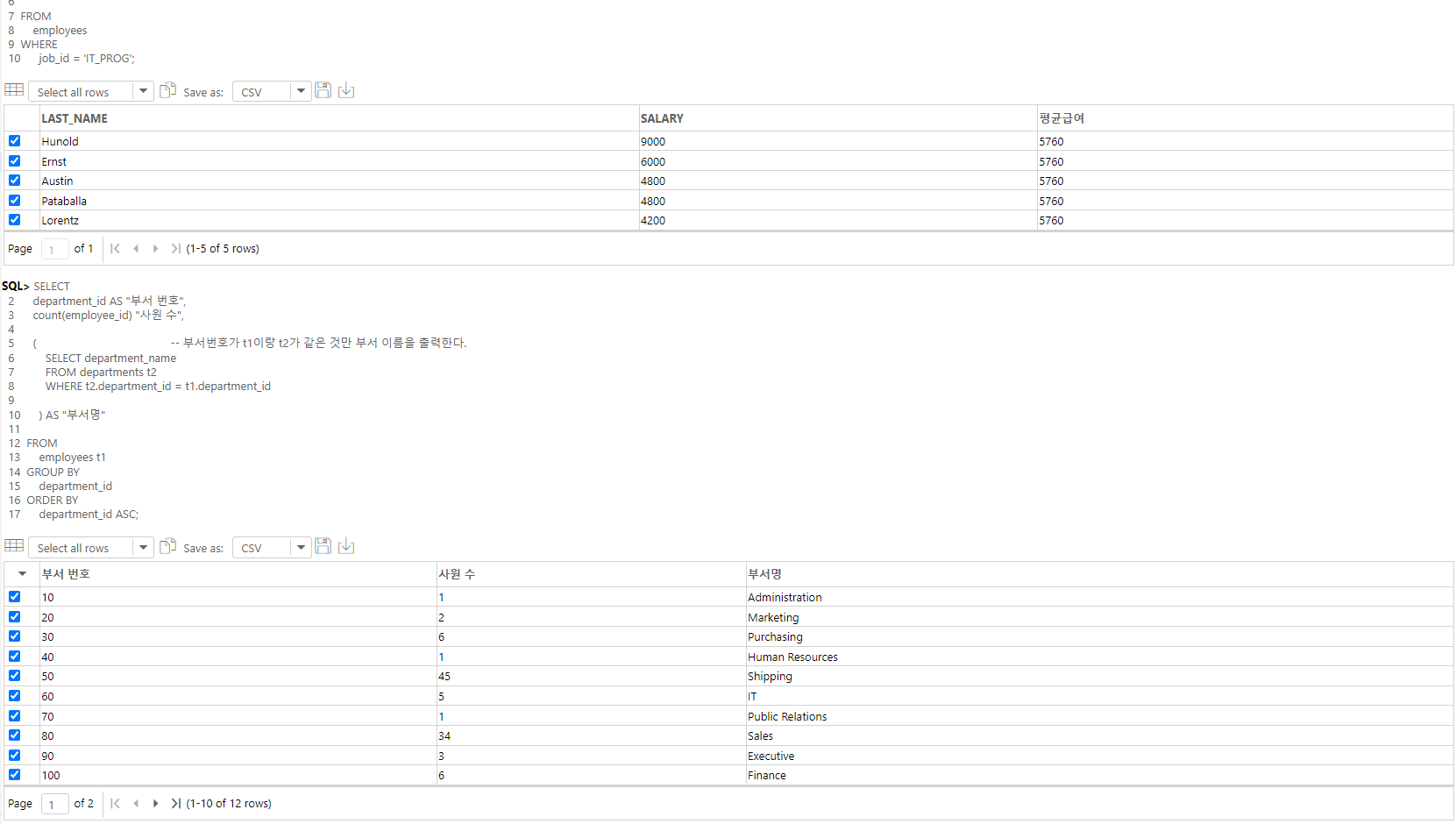
-- FROM절에 서브쿼리 사용하기 ( 효율성을 위해서 ) (***)
SELECT
last_name AS "사원명",
salary AS "월급"
FROM
-- employees
(
SELECT last_name, salary
FROM employees
WHERE salary >= 10000
) t;
-- WHERE
-- salary > 10000;
-- 컬럼 수가 아주 많은 테이블로부터 출력하고자 하는 컬럼의 수가 적을 때, 작성하게 되면 메모리 자원의 효율성이 떨어진다.
-- 왜냐하면 DB는 테이블을 메모리에 올려 놓고 작업하기에 필요한 것만 올려 놓는 것이 효율성이 좋다.
-- FROM 절에 나온 서브쿼리가 만들어낸 결과셋(테이블)을 "인라인 뷰"라고 부른다.

-- 우리 회사 전 직원 중에, 급여가 5000 달러 이상 받는, 부서번호의 목록을 출력해라
SELECT
DISTINCT department_id
FROM
employees
WHERE
salary > 5000
AND department_id IS NOT NULL
ORDER BY
department_id ASC;
-- DISTINCT를 사용해서 종복된 부서의 번호를 삭제해야 한다.(***)
-- 우리 회사 전 직원 중에, 급여가 5000 달러 이상 받는, 부서번호의 목록을 출력해라
SELECT
department_id AS "부서 번호",
count(employee_id) AS "사원 수"
FROM
employees
WHERE
salary > 5000
AND department_id IS NOT NULL
GROUP BY
department_id
ORDER BY
department_id ASC;
-- GROUP BY를 활용하여 중복값이 출력되지 않도록 설정하였으며, count를 활용해 해당 부서의 사원수가 몇명인지 출력하였다.
-- 우리 회사 전 직원 중에, 급여가 5000 달러 이상 받는, 부서번호의 목록을 출력해라 (서브쿼리 사용 버전)
SELECT
department_id,
department_name
FROM
departments
WHERE
department_id IN (
SELECT department_id
FROM employees
WHERE salary > 5000 AND department_id IS NOT NULL
)
ORDER BY
department_id ASC;
-- IN은 집합연산자이기에 중복값은 자동으로 지워주기에 중복값을 따로 지워줄 필요는 없다.
-- 하지만, 연산자는 FROM절에 사용할 수 없다! WHERE절에 사용해야 한다.

-- ------------------------------------------------------
-- 1. 복수 행 Sub-query (*****)
-- ------------------------------------------------------
-- 가. 하나 이상의 행을 반환
-- 나. 메인쿼리에서 사용가능한 연산자는 아래와 같음:
-- (1) IN : 메인쿼리와 서브쿼리가 IN 연산자로 비교수행.
-- 서브쿼리 결과값이 복수 개인 경우에 사용.
-- (2) ANY : 서브쿼리에서, > 또는 < 같은 비교 연산자를 사용하고자
-- 할 때 사용. 검색조건이 하나라도 일치하면 참.
-- (3) ALL : 서브쿼리에서 > 또는 < 같은, 비교 연산자를 사용하고자
-- 할 때 사용. 검색조건의 모든 값이 일치하면 참.
-- (4) EXISTS : 서브쿼리의 반환값이 존재하면, 메인쿼리를 실행하고,
-- 반환값이 없으면 메인쿼리를 실행하지 않음.
-- ------------------------------------------------------
-- ------------------------------------------------------
-- (4) EXISTS 연산자 사용한 복수행 서브쿼리 (***)
-- ------------------------------------------------------
-- 가. 서브쿼리 반환값이 복수 개.
-- 나. 메인쿼리의 값이, 서브쿼리에서 반환된 결과 중에 하나라도
-- 존재하는지 여부를 확인할 때 사용하는 복수행 연산자.
-- 다. 만일, 서브쿼리의 반환결과가 하나라도 없으면(false),
-- 메인쿼리의 결과셋 출력을 수행하지 않음. (**)
-- 라. 만일, 서브쿼리의 반환결과가 하나라도 있으면(true),
-- 메인쿼리를 수행. (**)
-- ------------------------------------------------------
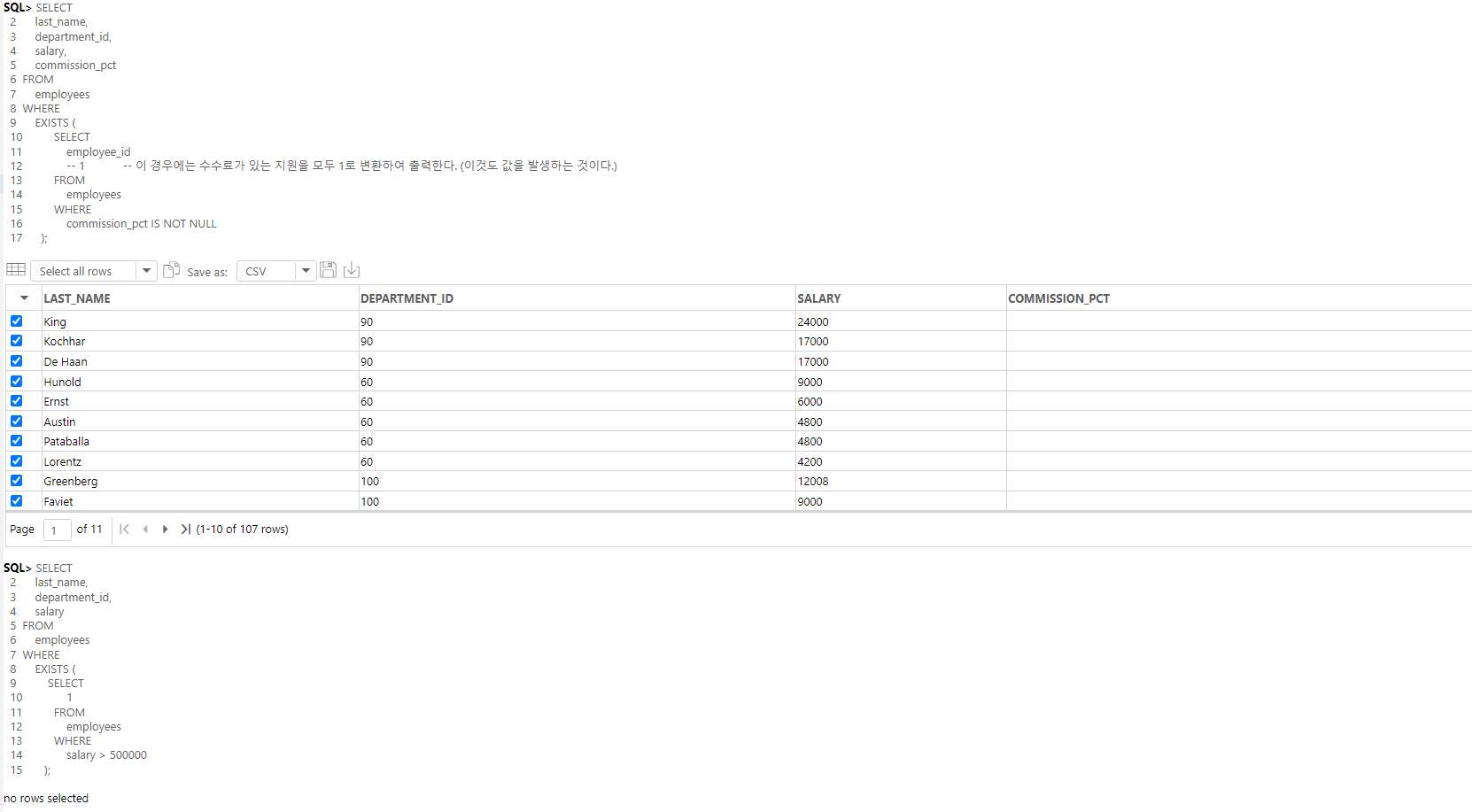
SELECT
last_name,
department_id,
salary,
commission_pct
FROM
employees
WHERE
EXISTS (
SELECT
employee_id
-- 1 -- 이 경우에는 수수료가 있는 지원을 모두 1로 변환하여 출력한다. (이것도 값을 발생하는 것이다.)
FROM
employees
WHERE
commission_pct IS NOT NULL
);
-- 메인쿼리에서 복수행 서브쿼리가 사용되었으므로, 복수값과 연산가능한 연산자를 사용할 수 있다. ( 복수행 연산자로 EXISTS 사용 )
-- EXISTS는 뒤에 (이 경우에는 서브쿼리에서) 값이 발생한다면 메인쿼리를 실행하라는 의미이다. (***)
-- 이때는 EXISTS에서 값이 발생하였기에, 메인쿼리를 실행하여 모든 직원의 이름, 부서, 월급, 수수료를 출력한다. (**)
-- 수수료가 없는 직원을 필터링하는 것이 아니다. 그저 메인쿼리의 결과셋 출력을 수행시킬지 말지를 결정하는 역할을 한다.(***)
-- EXISTS에서 값이 없을 경우에는 결과셋을 출력하지 않는다. ( 자세히는 메인쿼리는 실행은 하지만 결과셋을 출력하지는 않는다. )
-- no rows selected의 상태가 값이 없는 상태이다.
-- 서브쿼리는 1번만 실행되어 값이 결정된다.
-- EXISTS에서 값이 없을 경우에는 결과셋을 출력하지 않는 이유는 EXISTS로 인해 where이 항상 false가 되기에 메인쿼리는 실행은 되지만 조건을 만족하지 못해 출력하지 않는다.
SELECT
last_name,
department_id,
salary
FROM
employees
WHERE
EXISTS (
SELECT
1
FROM
employees
WHERE
salary > 500000
);
-- 이는 직원 중 1명이라도 500000달러 이상의 월급을 받는 직원이 있다면, 모든 직원을 출력하게 된다.
-- 이 경우 1명도 없기에 false가 전달되게 된다.
-- EXISTS는 조건으로 사용되는 편이다.
-- 우리회사 직원의 이름 중, Z로 시작하는 직원이 있으면, 전 직원의 사번과 이름을 출력해라 (***)
SELECT
employee_id,
last_name
FROM
employees
WHERE
EXISTS (
SELECT
last_name
FROM
employees
WHERE
last_name LIKE 'Z%'
);
-- Like 연산자를 통해서 Z로 시작하는 이름을 가지는 직원이 있으면, 메인쿼리를 실행해서 전 직원의 사번과 이름을 출력하게 하였다.
-- 우리 회사 직원 중 부서가 지정되지 않은 직원이 있다면, 그 직원의 사번과 이름과 부서번호를 출력해라
SELECT
employee_id AS 사번,
last_name AS 이름,
department_id AS 부서번호
FROM
employees
WHERE
EXISTS (
SELECT
LAST_NAME,
department_id
FROM
employees
WHERE
DEPARTMENT_ID IS NULL
)
AND DEPARTMENT_ID IS NULL;
-- 연결할때 AND 연산자를 까먹지 말고 사용하자!! (**)
-- 문제에 단서가 있을 때에는 EXISTS를 사용해야 한다. (**)
-- ------------------------------------------------------
-- 2. 다중컬럼 Sub-query
-- ------------------------------------------------------
-- 가. 서브쿼리에서, 여러 컬럼을 조회하여 반환
-- 나. 메인쿼리의 조건절에서는, 서브쿼리의 여러 컬럼의 값과 일대일
-- 매칭되어 조건판단을 수행해야 함.
-- 다. 메인쿼리의 조건판단방식에 따른 구분:
-- (1) Pairwise 방식
-- 컬럼을 쌍으로 묶어서, 동시에 비교
-- (2) Un-pairwise 방식
-- 컬럼별로 나누어 비교, 나중에 AND 연산으로 처리
-- ------------------------------------------------------
-- (1) Pairwise 방식 : 칼럼을 ( )로 쌍으로 묶어서 비교한다.
-- 부서별로 가장 많은 월급을 받는 사원정보 조회
SELECT
last_name,
department_id,
salary
FROM
employees
WHERE
( department_id, salary ) IN (
SELECT
department_id,
max(salary)
FROM
employees
GROUP BY
department_id -- NULL 그룹도 포함
)
ORDER BY
department_id ASC;
-- Pairwise 방식에서는 칼럼들을 소괄호 ( )로 묶어서 합쳐서 비교하게 된다.
-- 이 경우에는 원소가 모두 ( department_id, salary ) 쌍으로 들어가 있는 것이다. (***)
-- 문제 : 부서별 최소급여보다, 적은 급여를 받는 직원을 출력하라!
SELECT
last_name AS 이름,
department_id AS 부서번호,
salary AS 월급
FROM
employees
WHERE
( department_id, salary ) IN (
SELECT
department_id,
min(salary)
FROM
employees
GROUP BY
department_id -- NULL 그룹도 포함
)
ORDER BY
department_id ASC;
-- min을 활용하여 최소월급을 가지는 직원을 구하기 위해 ( department_id, salary ) 쌍으로 비교하였다.

-- ------------------------------------------------------
-- 3. 인라인 뷰(Inline View)
-- ------------------------------------------------------
-- 가. 뷰(View) : 실제 존재하지 않는 가상의 테이블이라 할 수 있음
-- 나. FROM 절에 사용된 서브쿼리를 의미 (***)
-- 다. 동작방식이 뷰(View)와 비슷하여 붙여진 이름
-- 라. 일반적으로, FROM 절에는 테이블이 와야 하지만, 서브쿼리가
-- 마치 하나의 가상의 테이블처럼 사용가능 (**)
-- 마. 장점: (***)
-- 실제로 FROM 절에서 참조하는 테이블의 크기가 클 경우에,
-- 필요한 행과 컬럼만으로 구성된 집합(Set)을 재정의하여,
-- 쿼리를 효율적으로 구성가능.
-- ------------------------------------------------------
-- Basic Syntax)
--
-- SELECT select_list
-- FROM ( sub-query ) alias ( 별칭을 필수로 작성해야 한다. ***)
-- [ WHERE 조건식 ];
-- 실제로는 존재하지 않는 테이블이 아닌 가상의 테이블이기에,
-- 별칭을 통해서 활용해야 하기에 병칭을 필수로 작성해야 한다. (***)
-- ------------------------------------------------------
-- 각 부서별 총 사원수, 월급여 총계, 월급여 평균 조회
-- ORACLE INNER JOIN ( Equal Join ) 방식
SELECT
e.department_id AS 부서번호,
sum(salary) AS "총 합계",
avg(salary) AS "평균 월급",
count(*)
FROM
employees e,
departments d
WHERE
e.department_id = d.department_id
GROUP BY
e.department_id
ORDER BY
e.department_id ASC;
-- 오라클 방식의 경우 테이블의 크기가 클 수록 자원이 비효율적으로 사용된다는 단점이 있다.
-- 인라인 뷰 방식
SELECT
e.department_id,
d.department_name,
총합,
평균,
인원수
FROM
(
SELECT
department_id,
sum(salary) AS 총합,
avg(salary) AS 평균,
count(*) AS 인원수
FROM
employees
GROUP BY
department_id
) e, -- 인라인뷰 크기가 12로 원래 employees 테이블과 비교하면 매우 줄어든 것을 알 수 있다.
departments d
WHERE -- FK PK
e.department_id = d.department_id -- 조인조건 ( 공통칼럼 지정 )
ORDER BY
e.department_id ASC;
-- 이 방식의 경우 오리지날 테이블의 크기를 줄여서 보다 효율적으로 사용하고자 하고 있다.
-- employees만으로도 문제를 해결할 수 있을 수도 있지만, employees에 있는 부서번호(department_id)는 FK이기에 중복과 NULL을 허용해
-- 반드시 모든 부서가 존재한다고는 확신할 수 없어 departments 테이블을 사용했어야 했다.

728x90
'KH 정보교육원 [ Java ]' 카테고리의 다른 글
| KH 50일차 - INSERT / UPDATE / DELETE / MERGE (***) (0) | 2022.05.09 |
|---|---|
| KH 49일차 - INSERT 문 (***) (0) | 2022.05.06 |
| KH 47일차 - ANSI JOIN / 서브쿼리 (*****) (0) | 2022.05.03 |
| KH 46일차 - Join ( 조인 ) (***) (0) | 2022.05.02 |
| KH 45일차 - CASE문 / 그룹 처리 함수 (***) / HAVING 절 (0) | 2022.04.29 |
댓글