
티스토리 뷰
-- -------------------------------------------
-- 1. 일반 (처리) 함수 - CASE문 ( 자바 : switch문 )
-- -------------------------------------------
-- 조건이 반드시 일치하지 않아도, 범위 및 비교가 가능한 경우에 사용하는 함수
-- -------------------------------------------
-- 문법1) 조건이 반드시 일치하는 경우
-- CASE column
-- WHEN 비교값1 THEN 결과값1
-- WHEN 비교값2 THEN 결과값2
-- ...
-- ELSE 결과값n ( 일치하지 않을 때의 디폴트값 )
-- END
-- -------------------------------------------
SELECT
salary,
CASE salary
WHEN 1000 THEN salary * 0.1
WHEN 2000 THEN salary * 0.2
WHEN 3000 THEN salary * 0.3
ELSE salary * 0.4
END AS "보너스"
FROM
employees;
-- 월급이 1000, 2000, 3000, 그 외일때를 구분하여 조건문으로 보너스 계산식을 지정하였다.
-- CASE의 경우에는 함수라기 보다는, CASE문이라고 많이 불린다.
-- 이 경우에는 decode와 같이 동등비교(=)연산자로만 비교하는 것이지, >=와 같은 것으로 비교하는 것이 아니다.

-- -------------------------------------------
-- 문법2) 조건이 반드시 일치하지 않는 경우
-- CASE
-- WHEN 조건1 THEN 결과값1
-- WHEN 조건2 THEN 결과값2
-- ...
-- ELSE 결과값n ( 일치하지 않을 때의 디폴트값 )
-- END
-- -------------------------------------------
SELECT
salary,
CASE
WHEN salary > 30000 THEN salary * 0.3
WHEN salary > 20000 THEN salary * 0.2
WHEN salary > 10000 THEN salary * 0.1
ELSE salary * 0.4
END AS "보너스"
FROM
employees
ORDER BY
salary DESC;
-- 조건이 반드시 일치하지 않더라도, 범위에 값이 해당한다면 조건문을 출력한다.
-- decode나 일치할때의 CASE와는 다르게, 이 경우 컬럼을 따로 작성하는 것이 아니라 조건에 컬럼을 활용한다. (**)
-- 조건은 위에서부터 아래로 단계별로 필터링하게 된다.
-- 그렇기에, 이 경우 첫번째 조건에 범위를 넓게 잡게 되면 범위에 따른 조건식형성이 잘못 될 수 있으니 확인해봐야한다.
-- CASE함수 ( 동등조건 )
SELECT
last_name,
salary,
CASE salary
WHEN 24000 THEN salary * 0.3
WHEN 17000 THEN salary * 0.2
ELSE salary
END AS "보너스"
FROM
employees
ORDER BY
salary DESC;
-- 동등조건을 활용한 CASE함수에서 월급을 활용한 내림차순으로 정렬하였다.
-- CASE 함수 ( 부등조건 )
SELECT
last_name,
salary,
CASE
WHEN salary >= 20000 THEN 1000
WHEN salary >= 15000 THEN 2000
WHEN salary >= 10000 THEN 3000
ELSE 4000
END AS "보너스"
FROM
employees
ORDER BY
salary DESC;
-- 이때 첫번째 조건의 범위는 20000 <= x < 15000, 두번째 조건범위는 15000 <= x < 10000, 세번째 조건범위는 10000 <= x이다.
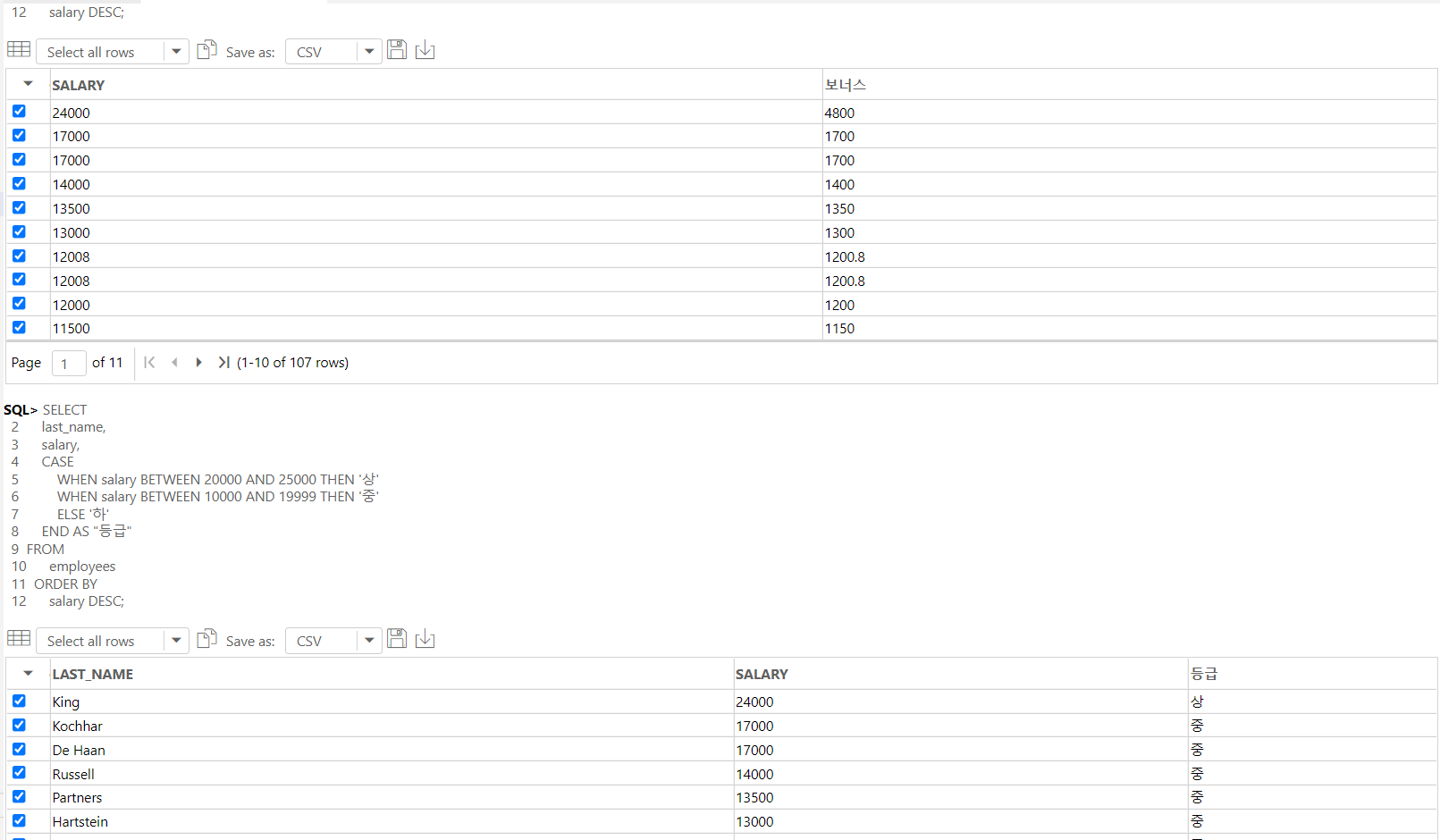
SELECT
last_name,
salary,
CASE
WHEN salary BETWEEN 20000 AND 25000 THEN '상'
WHEN salary BETWEEN 10000 AND 19999 THEN '중'
ELSE '하'
END AS "등급"
FROM
employees
ORDER BY
salary DESC;
-- 첫번째 조건에서 걸러졌으면, 두번째 조건에서는 판단하지 않는다는 점과 범위를 지정하지 않으면 결측치 NULL이 들어간다는 점을 주의해야 한다. (**)
-- between은 조건 범위가 이상 이하임을 알아야 한다.
SELECT
last_name,
salary,
CASE
WHEN salary IN(24000, 17000, 14000) THEN '상'
WHEN salary IN(13500, 13000) THEN '중'
ELSE '하'
END AS "등급"
FROM
employees
ORDER BY
salary DESC;
-- 위와 같이 조건문의 경우에는 연산자를 활용할 수도 함수를 사용하여 조건문을 작성할 수도 있다.
-- -------------------------------------------
-- 2. 그룹 (처리)함수
-- -------------------------------------------
-- 그룹 (처리)함수 구분 :
-- -------------------------------------------
-- (1) SUM - 해당 열의 총합계를 구한다
-- (2) AVG - 해당 열의 평균을 구한다
-- (3) MAX - 해당 열의 총 행중에 최대값을 구한다
-- (4) MIN - 해당 열의 총 행중에 최소값을 구한다
-- (5) COUNT - 행의 개수를 카운트한다 (**)
--
-- * 그룹 (처리)함수는, 1) 여러 행 또는 2) 테이블 전체에 대해,
-- 함수가 적용되어, 하나의 결과를 반환!
-- * 기본적으로 그룹 (처리)함수는 NULL값을 자동으로 제외한다.
-- * 함수의 위치는 select절이 아니어도 가능은 하다.
-- -------------------------------------------
-- -------------------------------------------
-- 1 ) 그룹 (처리)함수 - SUM
-- -------------------------------------------
-- 해당 열의 총합계를 구한다. ( * NULL값은 제외한다. )
-- -------------------------------------------
-- 문법) SUM( [ DISTINCT | ALL ] column )
-- DISTINCT : excluding duplicated values. ( 중복값 제외 )
-- ALL : including duplicated values. ( 중복값 허용, 디폴트값은 ALL이다. )
-- (if abbreviated, default)
-- -------------------------------------------
SELECT
sum(DISTINCT salary),
sum(All salary),
sum(salary)
FROM
employees;
-- 월급을 기준으로 중복값을 제외한 총 합계와 중복값을 허용한 총 합계를 구해 출력한다.
-- DISTINCT나 ALL 중 선택하여 작성하지 않으면, 자동으로 ALL로 선택되어 적용된다.

-- -------------------------------------------
-- 2 ) 그룹 (처리)함수 - AVG
-- -------------------------------------------
-- 해당 열의 평균을 구한다. ( * NULL값은 제외한다. )
-- -------------------------------------------
-- 문법) AVG( [ DISTINCT | ALL ] column )
-- DISTINCT : excluding duplicated values.
-- ALL : including duplicated values.
-- (if abbreviated, default)
-- -------------------------------------------
SELECT
avg(DISTINCT salary),
avg(ALL salary),
avg(salary)
FROM
employees;
-- 월급을 기준으로 중복값을 제외한 평균과 중복값을 허용한 평균을 구해 출력한다.
-- sum과 마찬가지로 DISTINCT나 ALL 중 선택하여 작성하지 않으면, 자동으로 ALL로 선택되어 적용된다.

-- -------------------------------------------
-- 3 ) 그룹 (처리)함수 - MAX
-- -------------------------------------------
-- 해당 열의 총 행중에 최대값을 구한다. ( * NULL값은 제외한다. )
-- -------------------------------------------
-- 문법) MAX( [ DISTINCT | ALL ] column )
-- DISTINCT : excluding duplicated values.
-- ALL : including duplicated values.
-- (if abbreviated, default)
-- -------------------------------------------
SELECT
max(salary)
FROM
employees;
-- 월급의 최대값을 구해서 출력한다.
-- -------------------------------------------
-- 4 ) 그룹 (처리)함수 - MIN
-- -------------------------------------------
-- 해당 열의 총 행중에 최소값을 구한다. ( * NULL값은 제외한다. )
-- -------------------------------------------
-- 문법) MIN( [ DISTINCT | ALL ] column )
-- DISTINCT : excluding duplicated values.
-- ALL : including duplicated values.
-- (if abbreviated, default)
-- -------------------------------------------
SELECT
min(salary)
FROM
employees;
-- 월급의 최소값을 구해서 출력한다.
-- + PC에서 시간정보는 long타입의 정수로 관리되고 있기에, max와 min을 적용할 수 있다.
SELECT
min( hire_date ),
max( hire_date )
FROM
employees;
-- 날짜 데이터의 경우에는 최근 시간일 수록 날짜 데이터가 크고, 오래된 시간일수록 날짜 데이터가 작다. (**)
-- 그렇기에 min은 가장 오래된 직원의 입사일자를, max에서는 가장 최근에 입사한 직원의 입사일자를 출력한다.

-- -------------------------------------------
-- 5 ) 그룹 (처리)함수 - COUNT (***)
-- -------------------------------------------
-- 행의 개수를 카운트한다. (* 컬럼명 지정하는 경우, NULL값을 제외한다. )
-- *을 선택하여 작성할 경우에는 모든 컬럼이기에 NULL도 포함이 된다.
-- -------------------------------------------
-- 문법) COUNT( { [[ DISTINCT | ALL ] column] | * } )
-- DISTINCT : excluding duplicated values.
-- ALL : including duplicated values.
-- (if abbreviated, default)
-- -------------------------------------------
SELECT
count(last_name),
count(commission_pct)
FROM
employees;
-- 값을 몇 개 가지고 있는지 확인해 준다. ( 수수료의 경우, 수수료를 가지고 있는 직원의 수를 카운트해준다. )
-- DISTINCT나 ALL을 작성하지 않을 경우에는 디폴트값으로 ALL이 들어가기에 중복값을 허용하여 카운트해준다.
SELECT
count(job_id),
count(DISTINCT job_id)
FROM
employees;
-- 처음에는 모든 직원의 직책을 출력하였으나, 두번째에서는 직책의 종류를 추출하기 위해서 DISTINCT을 작성하여 중복값을 제외하였다.
-- 해당 테이블의 전체 레코드 개수 구하기 ( * 주의필요 )
SELECT
count(*),
count(commission_pct),
count(employee_id)
FROM
employees;
-- count(*)를 통해서 해당 테이블의 전체 레코드 개수를 출력하였다. ( 이때는 NULL을 카운트해준다. )
-- count(commission_pct)와 count(employee_id)는 디폴트값으로 ALL이 들어갔으나, 이는 중복값을 허용한다는 의미이지
-- NULL값을 카운트해준다는 의미가 이니기에, 각각 수수료가 있는 직원의 수와 사원번호가 있는 직원의 수를 출력한다.
-- *를 활용하면 쉽게 카운트할 수 있다고 생각할 수 있으나, 사실상 NULL이 문제가 되어 시간이 오래걸릴 수 있으니 사용하지 않는 것이 좋다.
-- 차라리 총 직원의 수를 구하기 위해서라면, count(employee_id)와 같이 count(기본키)로 카운트하는 것이 좋다. (***)
-- -------------------------------------------
-- * 테이블 = 모든 속성을 가진 객체의 집합
-- * 인덱스 = 테이블의 키 속성들 + ROWID의 집합

-- -------------------------------------------
-- 3. 단순 컬럼과 그룹 (처리)함수 - 주의 : 함께 사용이 불가능!
-- -------------------------------------------
-- a. 단순컬럼 : 그룹 함수가 적용되지 않음
-- b. 그룹함수 : 여러 행(그룹) 또는 테이블 전체에 대해 적용
-- 하나의 값을 반환
-- -------------------------------------------
SELECT
max(salary)
FROM
employees;
-- max는 employees 전체에 대해서 적용한 것이지, employees 안의 salary에만 적용한 것이 아니다.
-- 전체 직원의 max를 구한거지 각 직원의 max를 구한 것이 아니다!
-- 단순컬럼과 그룹함수는 동시 사용이 불가!
SELECT
last_name, -- 107개 반환
max(salary) -- 1개 반환
FROM
employees;
-- 이 경우 not a single-group group function이라는 오류를 발생하게 된다.
-- last_name은 각 사원의 이름을 출력하여 107개를 반환해야 하는데, max는 테이블에서 단 1개만 출력하기에 오류가 발생한다.
-- 즉, 직계함수로 사용했을 때 이 의미는 각 직원의 이름을 출력한 후에, 각 직원별로 월급의 최대값을 출력하라는 오류가 생기는 것이다.

-- -------------------------------------------
-- 4. 그룹 (처리)함수 - GROUP BY 절
-- -------------------------------------------
-- (Basic syntax)
-- SELECT
-- [단순컬럼1, ]
-- ..
-- [단순컬럼n, ]
--
-- [표현식1, ]
-- ..
-- [표현식n, ]
--
-- 그룹함수1,
-- 그룹함수2,
-- ...
-- 그룹함수n
-- FROM table
-- [ GROUP BY { 단순컬럼1, .., 단순컬럼n | 표현식1, .., 표현식n } ]
-- [ HAVING 조건식 ]
-- [ ORDER BY caluse ];
-- -------------------------------------------
-- *주의할 점1:
-- GROUP BY뒤에, Column alias or index 사용불가!!!
-- *주의할 점2:
-- GROUP BY뒤에 명시된 컬럼은,
-- SELECT절에 그룹함수와 함께 사용가능!!
-- *주의할 점3:
-- ORDER BY절의 다중정렬과 비슷하게, 다중그룹핑 가능
-- *주의할 점4:
-- WHERE 절을 사용하여, 그룹핑하기 전에, 행을 제외시킬 수 있다!!
-- *주의할 점5:
-- HAVING 절을 사용하여, 그룹핑한 후에, 행(X)이 아니라, 그룹(OK)을
-- 제외시킬 수 있다!!
-- *주의할 점6:
-- WHERE 절에는 그룹함수를 사용할 수 없다!!
-- *주의할 점7:
-- GROUP BY 절은 NULL 그룹도 생성함!!
-- -------------------------------------------
SELECT
DISTINCT department_id -- NULL 포함
FROM
employees
WHERE
department_id IS NOT NULL;
-- DISTINCT를 통해서 중복값을 삭제한 하여 각 부서 번호를 출력하였다.
-- department_id는 NULL을 허용하기에 WHERE 조건문을 통해서 필터링을 진행하여 NULL값을 지웠다.
-- -------------------------------------------

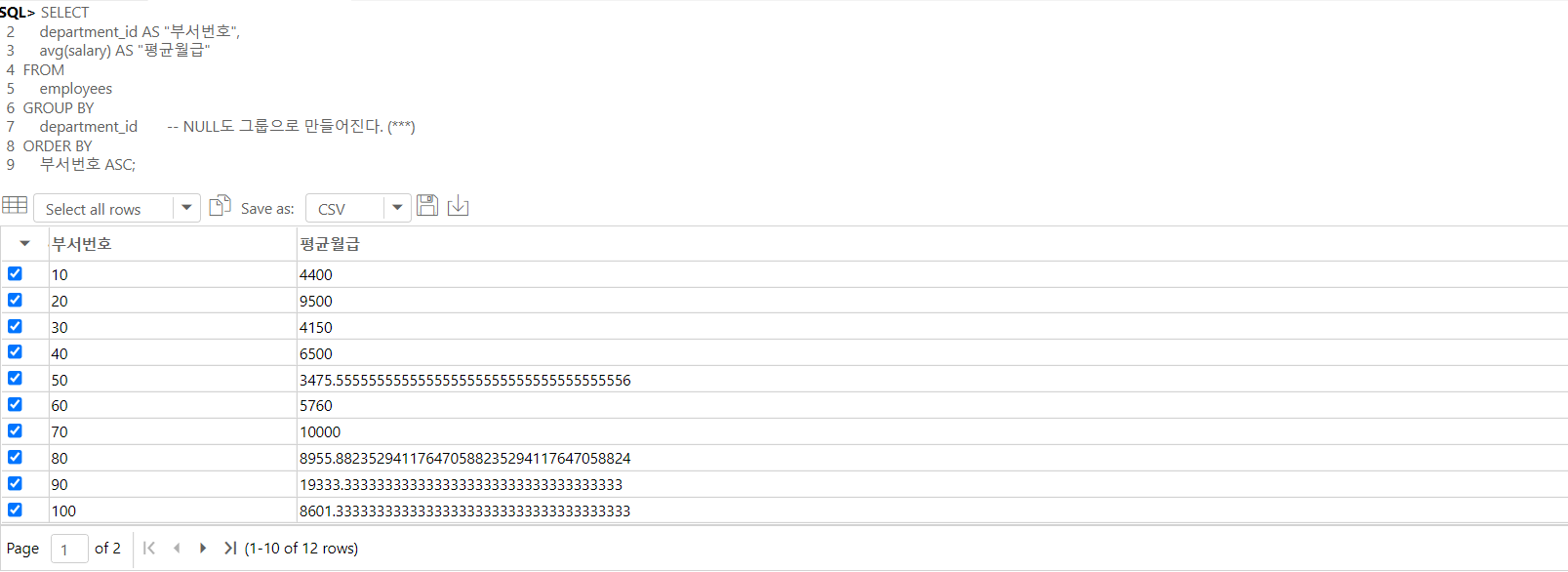
-- 부서별 GROUP BY ( AVG 함수 )
SELECT
department_id AS "부서번호",
avg(salary) AS "평균월급"
FROM
employees
GROUP BY
department_id -- NULL도 그룹으로 만들어진다. (***)
ORDER BY
부서번호 ASC;
-- 모든 사원을 각 부서별로 그룹화하여 각 부서의 평균월급을 구하였다.
-- department_id는 NULL을 허용하는데, where절로 NULL을 필터링하지 않았기에 NULL도 따로 그룹으로 형성되어 만들어진다.
-- 이 경우에는 모든 사월을 부서별로 그룹화를 한 후에, 부서번호라는 별칭의 부서번호와, 그룹화한 각 부서의 평균월급을 출력하여 오름차순으로 정렬한다.
-- 보통 단순 컬럼과 그룹 (처리)함수는 동시에 사용이 불가능하지만, 그룹화의 기준이 되는 컬럼의 경우 작성할 수 있다. (*****)
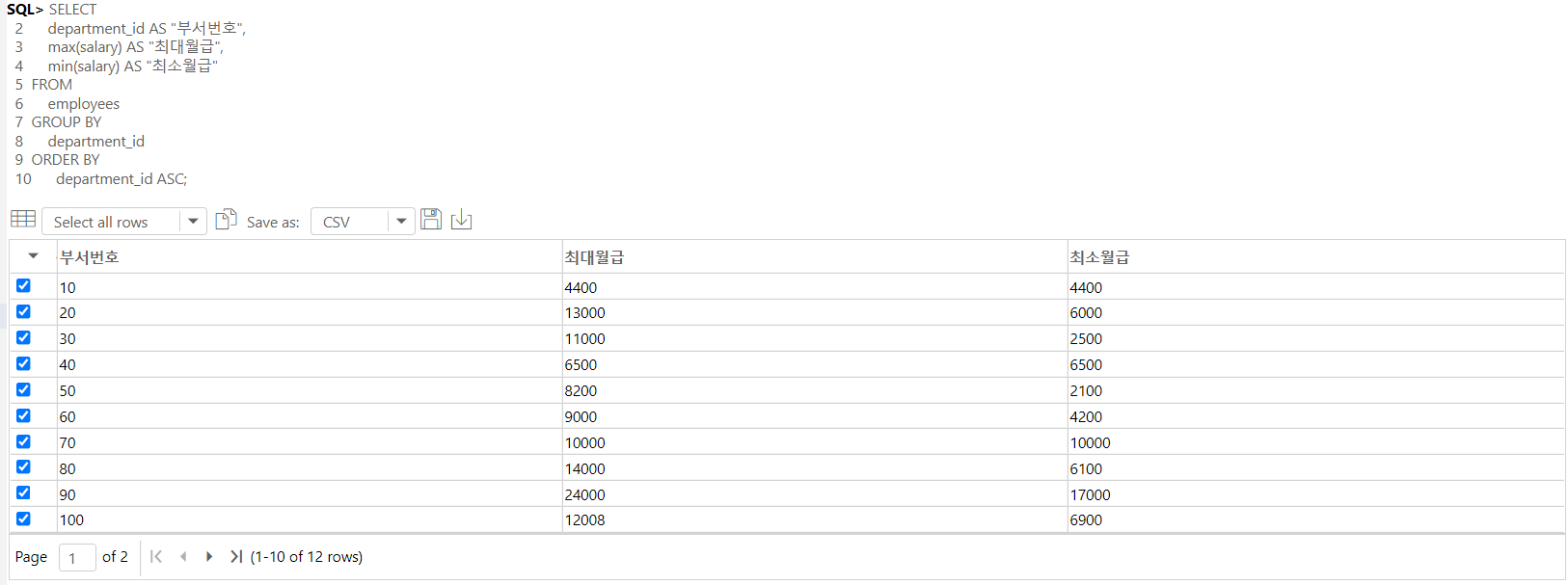
-- 부서별 GROUP BY ( MAX 함수 )
SELECT
department_id AS "부서번호",
max(salary) AS "최대월급",
min(salary) AS "최소월급"
FROM
employees
GROUP BY
department_id
ORDER BY
department_id ASC;
-- 모든 사원을 부서별로 그룹화한 후에, 부서번호, 각 부서별 최대 / 최소 월급을 부서번호를 기준으로 오름차순 정렬하였다.
-- GROUP BY절은 SELECT 절이전에 실행되기에, 별칭이나 컬럼 인덱스번호를 사용할 수 없다. (*)
-- 별칭이나 컬럼 인덱스의 활용은 SELECT 절 이후에 나오는 ORDER BY에서만 사용할 수 있다.
-- ORDER BY절의 정렬대상은 SELECT 절이 만들어낸 중간셋을 대상으로 하기에, 정렬기준도 SELECT절 내에 있는 것으로 선정해야 한다. (*****)
-- 보통 단순 컬럼과 그룹 (처리)함수는 동시에 사용이 불가능하지만, 그룹화의 기준이 되는 컬럼의 경우 작성할 수 있다. (*****)
-- 다중컬럼 GROUP BY (****)
SELECT
to_char( hire_date, 'YYYY' ) AS "년",
to_char( hire_date, 'MM') AS "월",
sum(salary)
FROM
employees
GROUP BY
to_char( hire_date, 'YYYY'),
to_char( hire_date, 'MM' )
ORDER BY
'년' ASC;
-- 입사한 년과 월이 같은 동기를 그룹화하여, 월급을 총 합계를 구하여 출력한다.
-- 보통 단순 컬럼과 그룹 (처리)함수는 동시에 사용이 불가능하지만, 그룹화의 기준이 되는 컬럼의 경우 작성할 수 있다. (*****)

-- -------------------------------------------
-- 5. HAVING 조건식
-- -------------------------------------------
-- GROUP BY 절에 의해 생성된 결과(그룹들) 중에서, 지정된 조건에
-- 일치하는 데이터를 추출할 때 사용 (*****)
--
-- (1) 가장 먼저, FROM 절이 실행되어 테이블이 선택되고,
-- (2) WHERE절에 지정된 검색조건과 일치하는 행들이 추출되고,
-- (3) 이렇게 추출된 행들은, GROUP BY에 의해 그룹핑 되고,
-- (4) HAVING절의 조건과 일치하는 그룹들이 추가로 추출된다!!!
--
-- 이렇게, HAVING 절까지 실행되면, 테이블의 전체 행들이, 2번의
-- 필터링(filtering)이 수행된다.
-- ( WHERE절: 1차 필터링, HAVING절: 2차 필터링 )
-- -------------------------------------------
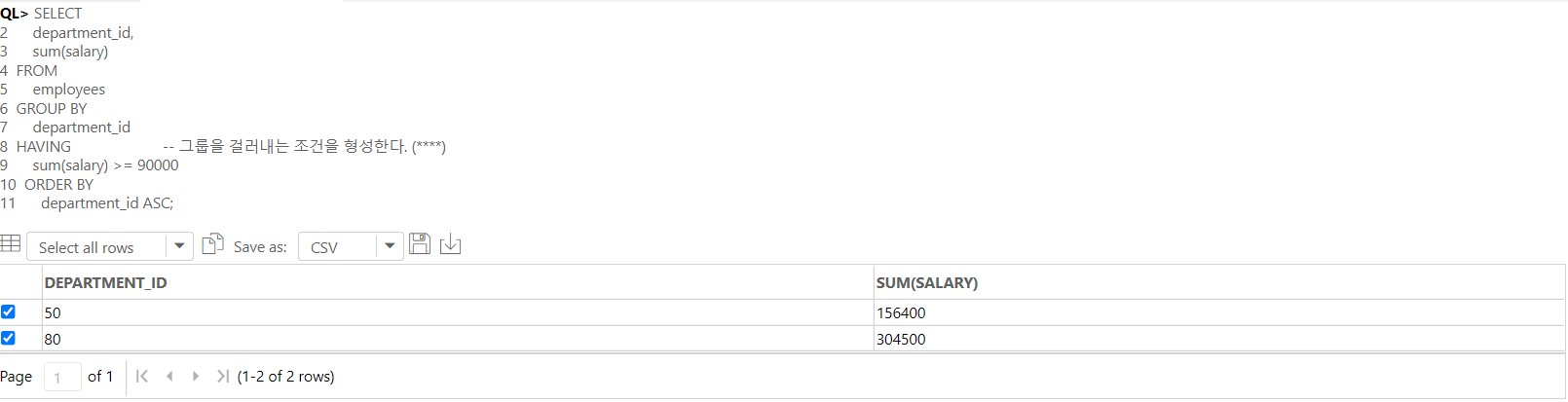
-- 각 부서별, 월급여 총 합계 구하기
SELECT
department_id,
sum(salary)
FROM
employees
GROUP BY
department_id
HAVING -- 그룹을 걸러내는 조건을 형성한다. (****)
sum(salary) >= 90000
ORDER BY
department_id ASC;
-- 직원을 부서별로 그룹화한 후에, 그룹의 월급 총 합계가 90000이상인 부서와 부서 월급여의 총합계를 부서를 기준으로 오름차순하였다.
-- HAVIG절은 그룹의 성질을 기준으로 조건을 작성해야 한다. ( 꼭 SELECT절에 있는 것이 아니어도 괜찮다. )
-- SELECT 문의 기본구조와 각 절의 실행순서를 잘 확인하면서, 작성해야한다.
-- 각 부서별 직원 수 구하기 (***)
SELECT
department_id AS "부서번호",
count( employee_id ) AS "사원수"
FROM
employees
GROUP BY
department_id -- NULL도 그룸화가 되어버린다.
ORDER BY
department_id ASC;
-- 모든 사원을 각 부서별로 그룹화를 한 후에 count를 활용하여 부서별 직원의 수를 카운팅하였다.
-- count를 사용할 때에는 NULL이 없는 컬럼을 사용하는 것이 좋다. ( 기본key 속성의 컬럼을 사용하는 것이 좋다. (***) )
-- 그 이유는 NULL은 카운트할 수 없기 때문이다.
-- count(*)를 활용해도 직원수가 나오기는 하지만 그렇게 되면 실행에 많은 부담을 주기에 피하는 것이 좋다.
SELECT
department_id AS "부서번호",
count( employee_id ) AS "사원수"
FROM
employees
GROUP BY
department_id
HAVING
count(salary) >= 6
-- HAVING
-- count(salary) >= 6 -- OK: 1st. filtering (for groups).
-- HAVING
-- salary >= 3000 -- XX: 각 그룹에 대해, 단순컬럼들만 사용불가
-- HAVING
-- department_id IN (10, 20) -- OK: GROUP BY절에 나열된 단순컬럼들은 사용가능
-- HAVING
-- department_id > 10 -- OK: GROUP BY절에 나열된 단순컬럼들은 사용가능
ORDER BY
department_id ASC;
-- HAVING 절은 GROUP(부서)의 성질을 가지는 절로 구성해야 한다. (***)

-- 각 부서별 월 급여 총계 구하기
SELECT
department_id,
sum(salary)
FROM
employees
WHERE
salary >= 3000 -- 1차 필터링
GROUP BY
department_id
HAVING
sum(salary) >= 90000 -- 2차 필터링
ORDER BY
department_id ASC;
-- 모든 사원 중에 월급이 3000 이상인 직원을 부서별로 구분한 후에, 부서의 월급 총합계가 90000이상인 부서를 부서번호를 기준으로 오름차순 정렬한다.

6. 관계대수
- 릴레이션에서 원하는 결과를 얻기 위해 수학의 대수와 같은 연산을 이용하여 질의하는 방법을 기술하는 언어를 관계대수라고 한다.
- 관계대수와 관계해석 :
- 1 ) 관계 대수 : 어떤 데이터를 어떻게 찾는지에 대해 처리 절차를 명시하는 절차적인 언어이며, DBMS 내부의 처리 언어로 사용된다.
- 2 ) 관계 해석 : 어떤 데이터를 찾는지에 대해서만 명시하는 선언적인 언어로 관계대수와 함께 관계 DBMS 표준 언어인 SQL의 이론적인 기반을 제공한다.
- + 관계대수와 관계해석은 모두 관계 데이터 모델의 중요한 언어이며, 실제로 동일한 표현 능력을 가지고 있다.
- + 조인 ( Join ) : 우리가 원하는 데이터가 여러 테이블에 흩어져 있는 경우, 이 테이블을 가로로 연결시킨 것
-- -------------------------------------------
-- 7. Cartesian Product 집합연산자에 대해서 알아보자!
-- -------------------------------------------
-- 두 테이블(== 집합) A, B가 있을 때, C/P = |A| x |B| (***)
-- -------------------------------------------
SELECT
*
FROM -- Cartesian Product
regions, -- 4개의 원소
departments; -- 27개의 원소
-- FROM절에는 테이블이 1개만이 아니라 N개가 올 수 있으며, 이때 구분자는 ' , '이며 Cartesian Product 집합연산이 이루어진다. (***)
-- 결과셋을 보면 108개가 출력되는데, 그 이유는 regions가 4개의 원소를 가지고 있고 departments가 27개의 원소를 가지고 있어 4*27 = 108이기 때문이다.
728x90
'KH 정보교육원 [ Java ]' 카테고리의 다른 글
| KH 47일차 - ANSI JOIN / 서브쿼리 (*****) (0) | 2022.05.03 |
|---|---|
| KH 46일차 - Join ( 조인 ) (***) (0) | 2022.05.02 |
| KH 44일차 - 문자 / 숫자 / 날짜 / 변환 처리 함수 (***) (0) | 2022.04.28 |
| KH 43일차 - SQL문의 기본 연산자 (0) | 2022.04.27 |
| KH 41 ~ 42일차 - SQL (0) | 2022.04.26 |
댓글